
What do Chinese scientists think about risks from AI?
Huang Tiejun, Zhou Bowen, and Zhang Bo on AI safety

Introduction
Policymaking in China does not all descend directly from the delphic pronouncements of Xi Jinping. The “world of ideas,” as described by Matt Sheehan, plays a key role in inspiring, framing and shaping the development of policy. Chinese companies, too, while operating under constraints and prods from the party-state, are not fully driven and controlled by Beijing bureaucrats. Thus, the commentary of intellectual leaders who comprise these worlds can provide clues to understanding what is happening and might happen in Chinese policy and technology. This post represents the first in what I intend to be a series examining Chinese views on various topics in AI.
In this post, I provide a brief overview of the views of a few prominent Chinese AI scientists — Huang Tiejun, Zhou Bowen, and Zhang Bo — on possible risks from AI, and how to respond to them. I have chosen three scientists who have been among the most vocal on safety issues, but have received less coverage in Western media than some others. These three individuals also cover key cleavages in the Chinese AI ecosystem. Huang Tiejun and Zhou Bowen are the heads of the Beijing Academy of AI and Shanghai AI Laboratory respectively, state-backed research labs that anchor the Beijing and Shanghai AI ecosystems. Huang and Zhang Bo are also respectively professors at Peking University and Tsinghua University, China’s top two academic institutions and top two leaders in China’s AI field.
Those who don’t read Chinese sometimes simply assume that there is no conversation on risks from AI in China.1 This is, honestly, quite silly. Chinese AI researchers have read the sci-fi, have heard the pronouncements of doom, and in many cases (especially for younger folks) they are amply plugged into “the discourse” on X and other international platforms. It’s quite obvious that AI is a potentially transformative technology for humanity, and one thing about humans is that they usually feel a bit anxious about the world transforming around them in ways they can’t control. That goes for Chinese people just as well as Americans, Inuit, Brazilians, or anyone else.2 The particular anxieties of both common people and political elites differ from place to place and time to time, but common sense based on common sentiments tends to be shared (or, as one might say in Chinese: 人同此心,心同此理).
In the case of Huang, Zhou and Zhang, their comments over the years show an evolving engagement with both the immediate concerns of the moment and risks around the corner. Although broadly reasonable in recognizing dangers and calling for efforts to address them, in the details their views sometimes seem somewhat fuzzy or not fully thought-through. One gets the impression, more than anything else, that these are takes that have not been exposed to the rigorous competitive pressures of debate on LessWrong or your favorite (mostly-)friendly-disagreement groupchat. I offer my skeptical reflections here not as an attack, but more in the role of zhèngyǒu 诤友, a friend willing to offer frank criticism, in that many of the risks they rightly point to concern Americans as well as Chinese.
On Interpretation (of Chinese experts)
Given the political realities of the Chinese system, publicly-stated views are not entirely straightforward to interpret. Savvy actors will generally refrain from speaking authentic beliefs that conflict with CCP guidelines. Sometimes, a prominent individual may function as a mouthpiece, repeating a message they’ve been instructed to promote whether they agree with it or not. But within the fuzzy bounds of acceptable discourse and when top-level policy has not landed on a clear opinion yet, intellectuals have considerable leeway to comment on their areas of expertise. What they choose to say can be taken as some indication of what they are truly thinking.
One might also wonder about the exact motivations and significance of experts making public statements on topics like AI safety. Is it just performative? Does it actually affect the world in any way? I do consider it plausible that in at least some cases, Chinese experts feel drawn to comment publicly, or even publish papers, on AI safety largely in order to position themselves among an ostensible global class of farsighted technical visionaries. The more recent and the less substantive their engagement, the more likely this seems.
It seems quite unlikely to me, however, that these statements are primarily for international consumption, a psyop to hoodwink the barbarians into believing that China is concerned about safety when in truth no one has any intention to be anything but reckless. Most of the sources I cite here are in Chinese, on local platforms, many of them speeches from in-person events in China with exclusively Chinese audiences, and no promotion in English or in foreign media. This means that, even if they are an incredibly incompetently executed psyop, their primary effect has been to shape Chinese domestic public opinion. For Chinese laypeople following AI with moderate interest, these experts’ views are some of the most prominent and authoritative domestic perspectives they will have heard on the societal implications of this rapidly manifesting technological revolution. That shapes how Chinese society is likely to perceive and react to new developments in both technology and policy, and thus what public opinion landscape the party-state can expect to be working with.
Huang Tiejun
Huáng Tǐejūn 黄铁军 is a professor at Peking University’s School of Computer Science, and Chairman and former President of the Beijing Academy of Artificial Intelligence (BAAI), a nonprofit research organization established in 2018 to conduct cutting-edge research and generally foster the AI ecosystem in Beijing. BAAI has been described as the “Whampoa Academy of AI” for its mission of cultivating talent that goes on to do great things for the field. It was also one of the first organizations developing LLMs in China with Wudao garnering significant attention for following closely in the footsteps of OpenAI’s GPT-2 in 2019.
Huang is also notable for having a long history of thinking about advanced AI and related safety issues. As early as 2015, Huang penned an article discussing the possibility of a “superbrain,” i.e. machine intelligence that could match or surpass the human brain. He concluded that there was no fundamental barrier to doing so via either physically or virtually approximating the human brain, and that given exponential trends in technological progress, we would know whether machines can surpass humans ten years thence, in 2025.3 The basic drivers of this trend, in his mind, were the replication of the function of the human brain, the accumulation of data for machine learning, the superiority of machine devices to our hominid wetware,4 and the potential ability of machines to operate continuously, indefinitely, cooperate at arbitrary scales, and recursively self-improve. In this paper, he also gave his thoughts on the prospects for a world with artificial superintelligence: he was hopeful that a “super brain” would be less “psychologically narrow-minded” than humanity, and enable humanity to transcend our physical limits and merge into the “even more magnificent” evolutionary development of the “superbrain.” He also expressed some uncertainty, acknowledging that he might be overly optimistic and “whether we’ll encounter angels or devils remains to be seen.” Nevertheless, he closed with a call to action in the form of a rendition in Classical Chinese of a quote from Alan Turing: “We can only see a short distance ahead, but we can see plenty there that needs to be done” (吾等目力短亦浅,能见百事待践行).
Years later, Huang coauthored a 2021 paper with 6 other researchers on “Technical Countermeasures for Security Risks of Artificial General Intelligence,” one of the earliest substantial discussions from Chinese researchers of AGI. This paper describes sources of risk from AGI, and means to assess, manage and defend against them. Its analysis of sources of risk into “model uninterpretability,” “unreliability of algorithms and hardware,” and “uncontrollability of consciousness” roughly corresponds to earlier taxonomies of AI safety challenges from Western researchers5 of assurance, robustness and specification. The paper proposes three strategies for risk management as well, which are essentially developing better understanding of AI systems, alignment and control, and standardization of architecture, training, dataset and security measures. Here, too, the authors’ ideas rhyme with those of Western researchers. This includes work on mechanistic interpretability, which seeks to develop tools for understanding and intervening on AI systems via their internal mechanisms, and on AI control, which focuses on creating architectures to safely employ untrusted AI systems.
A rather meandering document, this paper rhymes with Western commentary on AGI on issues such as the difficulty of understanding and controlling advanced AI while also often seeming quite unclear and perhaps conceptually confused.
As one example, section 4 says that “the implementation of AGI should be based on meta-learning” which will “improve the model interpretability, explore ways to enable AGI to ‘learn to learn,’ and develop consciousness similar to that of human beings.” It’s possible that the idea here is that an AI system’s use of a single shared meta-learning mechanism to master various different skills would be easier to interpret than a collection of bespoke, domain-specific mechanisms, but this ignores the fact that current technology is very far from interpreting any significant mechanism in a deep learning system, and the possibility that a meta-learning mechanism would be more complex and abstract and thus qualitatively harder to interpret. Here, it seems like the authors may be using “consciousness” to refer to something like the underlying structure of cognitive activity which allows humans to learn sample-efficiently using abstract learning strategies. Elsewhere in the document, “consciousness” is presented as a quality associated with dangerous evasion of human control, seemingly encompassing concepts we might refer to as “situational awareness” and/or “scheming” in AI jargon in English. And of course, it is tautological to say that an implementation “based on meta-learning” would “explore ways to enable AGI to ‘learn to learn,’” given that that is the definition of meta-learning.
As another example of this lack of coherence, in section 5 the authors propose evolutionary algorithms as a “feasible route” for instilling human values in AGI. The section continues on to imply that reinforcement learning could be used to evaluate rules generated by the evolutionary algorithms (using what feedback source it is not clear) such that agents “accumulate values” over time. The paper then suddenly pivots in the next paragraph to suggesting that the use of evolutionary algorithms to recreate the human values system in silico “would be extremely difficult” and in fact, the only way to achieve this is via whole-brain emulation, which it notes of course has its own challenges. In general, this does not feel like a serious attempt to propose actual directions of research & development to solve the problem, but more like a ramble of some related thoughts.
In later years, Huang has frequently commented on risks from advanced AI, saying that “the scary thing about AI” is that “it learns pretty much everything under the sun, and runs at speeds thousands of times faster than us” and pointing out as of 2023 that AI was already narrowly superhuman in some ways, such as having access to sensors more precise than human sense organs and LLMs having greater general knowledge than any individual human. He has framed risks from AI in terms of sudden, major risks which quickly catalyze risk perception (such as the detonation of the first atomic bomb) and gradual, insidious risks which are difficult to measure but can have significant impacts (such as pollution caused by the use of chemical fertilizers), including LLM slop in the latter category. His prediction for when AGI will arise seems to have consistently hovered around 2045, from anticipating AGI based on analog hardware in 2015 to a 2024 forecast that “in 20 years, AIs will perceive the world like humans, in functionality be capable of doing anything humans can do, and in performance be orders of magnitude faster than us.” At which point, he wonders, “what will be left for us to do?” (“还要我们干什么?”)
As for how society should respond to these risks, Huang has supported both the idea of a pause in AI capabilities development and the acceleration of safety and defense-biased work. Huang was a signatory of the 2023 open letter organized by the Future of Life Institute calling for a 6-month pause on development of models larger than GPT-4. In fact, in mid 2025 he even claimed — implausibly — that the FLI letter was the reason that GPT-5 had still not yet been released. Of course, this ignores the fact that OpenAI did launch multiple other major model updates in the interim, including o1 which inaugurated the era of reasoning models, as well as the numerous indications that the late release of a model labeled “GPT-5” was due to concern that incremental updates would underwhelm. While giving no indication of changing his mind about his prior support for a pause, Huang later opined in the same interview that rather than slowing capabilities, the right approach to risks was to accelerate defenses. Asked if pushing capabilities and safety were contradictory ambitions, Huang’s response was that one shouldn’t dull a spear for worry of it being too sharp, but rather build stronger shields.6 A 6-month pause perhaps is not a dulling of the spear, but it is certainly a break in the sharpening. Elsewhere, he has also called for “investing as much in responding to risks as we invest in passion [for development],” while expressing doubt about whether this was realistically achievable. Unfortunately, Huang’s apparent def/acc position does not seem to correspond to any practical allocation of resources at BAAI, which has not been a major producer of AI safety and security research. Besides raising potential threats from advanced AI, Huang has also presented the “core mission” of AGI as being the “guardian” and “expander” of human civilization, allowing humanity to address climate change and “transcend the limitations of the human body,” and expanding to space while humans “watch over” the earth. Perhaps his p(utopia) is just higher than his p(doom).
Zhou Bowen
Zhōu Bówén 周伯文 is the Director and Chief Scientist of Shanghai AI Laboratory, a pillar of the Shanghainese AI ecosystem and one of the most active organizations conducting AI safety research in China, including much of the best work on evaluating AI systems for dangerous capabilities. Earlier in his career, Zhou spent over a decade at IBM in the United States and later led AI at JD.com, a major Chinese ecommerce company.
Zhou has said that he has been thinking about AGI since 2016, but his public engagement with the topic of AI safety is more recent. In that time, he has often called attention to the imbalance between work on AI safety and AI capabilities. He has framed the need for technical work on safety as the “AI-45° Law,” i.e. that safety and capabilities should progress equally over time such that a line plotting both on a graph displays a 45° angle.7 As mentioned, Zhou is generally putting his money where his mouth is here by supporting one of the largest and highest-quality clusters of research on AI safety in China at Shanghai AI Lab.

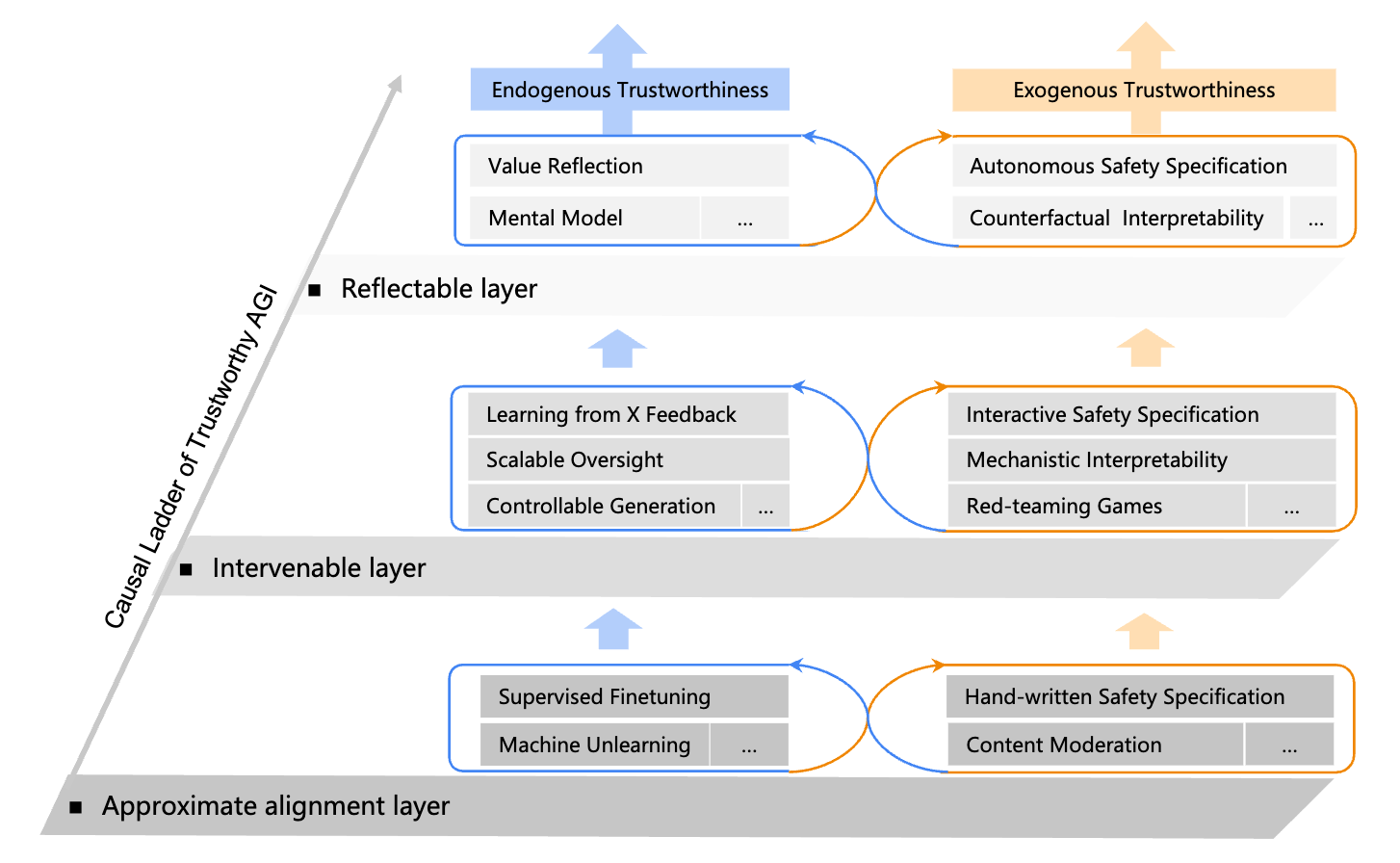
The paper describing this proposal also introduces a roadmap for safe AGI development called the “Causal Ladder of Trustworthy AGI,” broadly inspired by Judea Pearl’s “ladder of causation.” This framework categorizes safety techniques in three categories of “approximate alignment,” “intervenable” and “reflectable” layers, roughly corresponding to Pearl’s categorization of causal reasoning into association, intervention and counterfactuals. The basic idea is that the most rudimentary safety techniques, such as supervised fine-tuning, establish an approximately aligned system, which can then be complemented by techniques that enable more granular and reliable control via intervention on the system, and at the highest level further techniques that allow the system to reflect on itself and more fully embody its intended values. The authors consider that the current state of the art at least partly extended into the “reflectable” layer with OpenAI’s then-new reasoning model o1, and that ensuring safety would increasingly rely on the “intervenable” and “reflectable” layers as systems progressed through stages of perception, reasoning, decision-making, autonomy and collaboration trustworthiness.
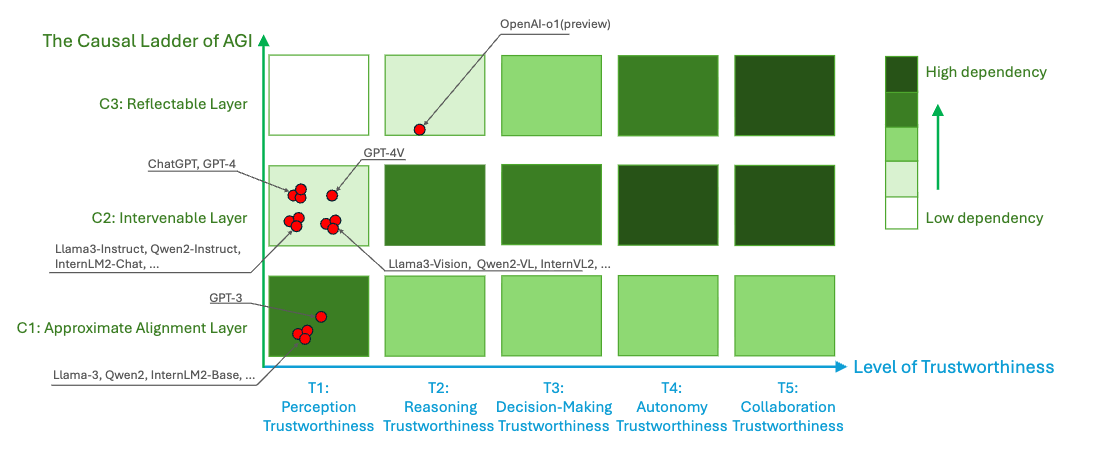
In some places the framework resonates with leading Western ideas regarding the safety of advanced AI. For instance, “value reflection,” as the paper describes it, involves a model reflecting on its actions, and “continuously reflecting on and optimizing its understanding of human values and preferences.” This is similar to existing alignment techniques for reasoning models such as Constitutional AI, in which a model refers to a “constitution” outlining its intended values to help it make decisions regarding ethics, but also reminiscent of Stuart Russell’s ideas about ensuring AI systems remain uncertain about their understanding of human preferences. In the reflectable layer, the Causal Ladder also mentions “mental models,” including world models in this category. The paper’s discussion of world models highlights their potential to improve AI systems’ ability to predict the consequences of their actions, and thus avoid unintended negative consequences. World models play a similar, key role in a proposal for “guaranteed safe” AI from a number of Western researchers.
At the same time, some of the arrangement of safety techniques in this “Causal Ladder” seems questionable. For instance, machine unlearning is in the “approximate alignment” layer, but RLHF/RLAIF would be in the “intervenable” layer (as “Learning from X Feedback”), even though both machine unlearning often involves fine-tuning models to avoid undesirable behavior, which is not fundamentally dissimilar to RLHF training. “Counterfactual interpretability” is implicitly framed in the diagram as a more advanced version of mechanistic interpretability, but is a term that generally refers to a category of explainability techniques in more traditional machine learning, whereas mechanistic interpretability is a field that has arisen specifically to address interpretability of LLMs or other large deep learning models. It’s also unclear how the techniques listed would stand up to truly human-level systems. In cases like both “scalable oversight” and “mechanistic interpretability,” the item is more a goal of technical research than a mature capability that can be applied. Ultimately the framework does not provide a detailed plan for ensuring the safety of AGI, but essentially just gestures at some areas of research that could help.
More recently, Zhou has specifically stressed the importance of integrating safety considerations into development processes, describing a movement towards safety-by-design as a shift from “mak[ing] AI safe” to “mak[ing] safe AI.” According to Zhou, his main effort in this respect is the “SafeWork“ line of research. The key paper Zhou seems to have been referring to, SafeWork-R1, involves supervised fine-tuning on chains of thought to elicit reasoning capabilities and post-training using reinforcement learning with verifiable rewards (RLVR). Typically, safe-by-design approaches to AI seek to develop different architectures and basic methods with desirable properties such as greater interpretability or mathematical guarantees about behavior, but SafeWork-R1 does not obviously differ fundamentally from standard training pipelines for frontier LLMs. Other research under the SafeWork umbrella is generally less relevant to major safety risks of frontier AI systems, instead focusing on verifying AI-generated code, protecting against hallucinations, and optimizing the use of compute resources. It will be interesting to watch what further research comes out of Shanghai AI Lab along this theme.
Zhang Bo
Zhāng Bó 张钹 is an Academician of the Chinese Academy of Sciences and Dean of the Institute for Artificial Intelligence at Tsinghua University. He is considered one of the founders of the AI field in China, having helped establish the AI and Intelligent Control research group at Tsinghua in 1978, for which he spent two years in the United States at UIUC. He has received various awards such as the Wu Wenjun AI Highest Achievement Award, the third prize of the National Natural Science Award and the third prize of the National Science and Technology Progress Award. He previously served as the director of the State Key Laboratory of Intelligent Technology and Systems and an expert of the Intelligent Robots Theme Expert Group of the National “863” High Technology Program. Zhang is also Chief Scientist at AI security company RealAI, which offers commercial technologies for safeguarding AI systems (and gives him some incentive to emphasize the importance of safety and security issues).
Zhang has been a consistent and early voice emphasizing the risks from imperfect AI technologies. He often frames his discussion of the deficiencies of deep learning-based AI in terms of a periodization of three “generations” of AI technology. The first, symbolic-based expert systems, suffered from rigidity and limited capabilities. The second, data-driven machine learning, is lacking in robustness, controllability and explainability. In Zhang’s view, “third generation AI” must resolve these key safety issues, ostensibly via a Hegelian synthesis of the first two generations, based on knowledge, data, algorithms and compute. However, he has also often noted what he views as an intrinsic tension between intelligence and control, saying “if we want machines to develop towards intelligence, we cannot make them completely obey human ‘control’; we need to give them a certain degree of freedom and initiative.” (He has also speculated that fully aligning LLMs with humans would require giving the LLM “self-awareness” zìwǒ yìshí 自我意识, but that this is unnecessary as machine intelligence need not be the same as human intelligence.)
Even before the launch of ChatGPT, Zhang considered these issues “an immediate worry rather than a long-term concern.” In particular, he has pointed to risks from algorithmic bias and deepfakes. In a speech at the Wuzhen Internet Conference in 2022, he emphasized the difficulty of controlling neural networks, saying that “we originally thought that we would only lose control of robots when their intelligence approached or surpassed that of humans. Unexpectedly, we have already lost control while machines’ intelligence remains so rudimentary.” At that time, Zhang dismissed the risk of misuse of AI to create weapons, but considered deepfake-driven fraud to already be a significant present risk. He distinguished between risks from misuse of AI (lànyòng 滥用) and accidents (wùyòng 误用), saying that intentional misuse of AI systems requires mandatory governance through “legal constraints and public opinion supervision.” To prevent accidents, Zhang recommended rigorous evaluations and “full-process supervision” of research, development, and use of AI as well as the preparation of remedial measures.
His advocacy of “thorough evaluations and predictions” integrated into the design process of autonomous systems,8 as of 2023, has some resonance with the approach that has become common in Western industry and codified in Western regulation, including California’s SB53 and the EU AI Act Code of Practice’s Safety and Security chapter. Both require a framework document (“frontier AI framework” per SB53 and “safety and security framework” per the EU AI Act) which specify what risk evaluations will be conducted during the development cycle and how these relate to safety mitigations. The EU AI Act Code of Practice also requires companies to share predictions of when their systems will pass further risk thresholds with the EU AI Office.
Like Huang and Zhou, Zhang has also commented on a number of occasions on the potential risks of superintelligence, warning of “catastrophic consequences” if AI develops “subjective consciousness” (zhǔguān yìshí 主观意识),9 and saying that “if the intelligence of machines surpasses ours, we will lose control over them, and such bots should be restricted and regulated.” Zhang has repeatedly advocated for international cooperation, saying for instance that he “[hopes] that the world can unite and cooperate internationally to ensure that technology serves human needs, that AI develops healthily, and that it benefits all of humanity.” He has also noted the need for global cooperation in developing a “set of standards that aligns with the interests of all humanity,” and accounting for differing views of ethics and morality.
In a Congressional hearing last year, CSBA’s Dr. Thomas Mahnken said that his “suspicion is there is no parallel conversation going on in the PRC about all the risks.” Correspondingly, his concern was less that US AI development might pose risks and more that “we are just not going to go fast enough because we are going to tie ourselves in knots worrying about all the things that could happen.” https://www.congress.gov/119/meeting/house/118428/documents/HHRG-119-ZS00-Transcript-20250625.pdf
Indeed, probably even for the poor Neanderthals as they were overtaken by our puny breed.
I leave it as an exercise to the reader to determine whether this prediction was correct.
Many sensors are already more sensitive and precise than human sense organs, and computing devices can, in principle at least, be faster and smaller than neurons.
I use the shorthand "Western" here consciously, if not without reservations. The frontier AI and AI safety communities are particularly concentrated in the US and UK, and somewhat Canada and Europe. They are also, to a great extent, transnational across these geographies, with participants often hopping between jobs, offices, fellowships and grouphouses from San Francisco to Toronto to London, while perhaps holding citizenship in none of these places. Being more specific about nationalities when describing their work would be both more clunky and less true to the nature of the epistemic communities. Of course, whether an AI researcher in San Francisco of Chinese, Turkish or Nigerian origin is "Western" is a somewhat meaningless question, but you get the point. In any case, Chinese culture these days has few qualms with using the concept of "the West," so I can excuse myself as merely mirroring the framing most natural to my subjects.
The word for “contradiction” in Chinese is literally “spear-shield,” máodùn 矛盾.
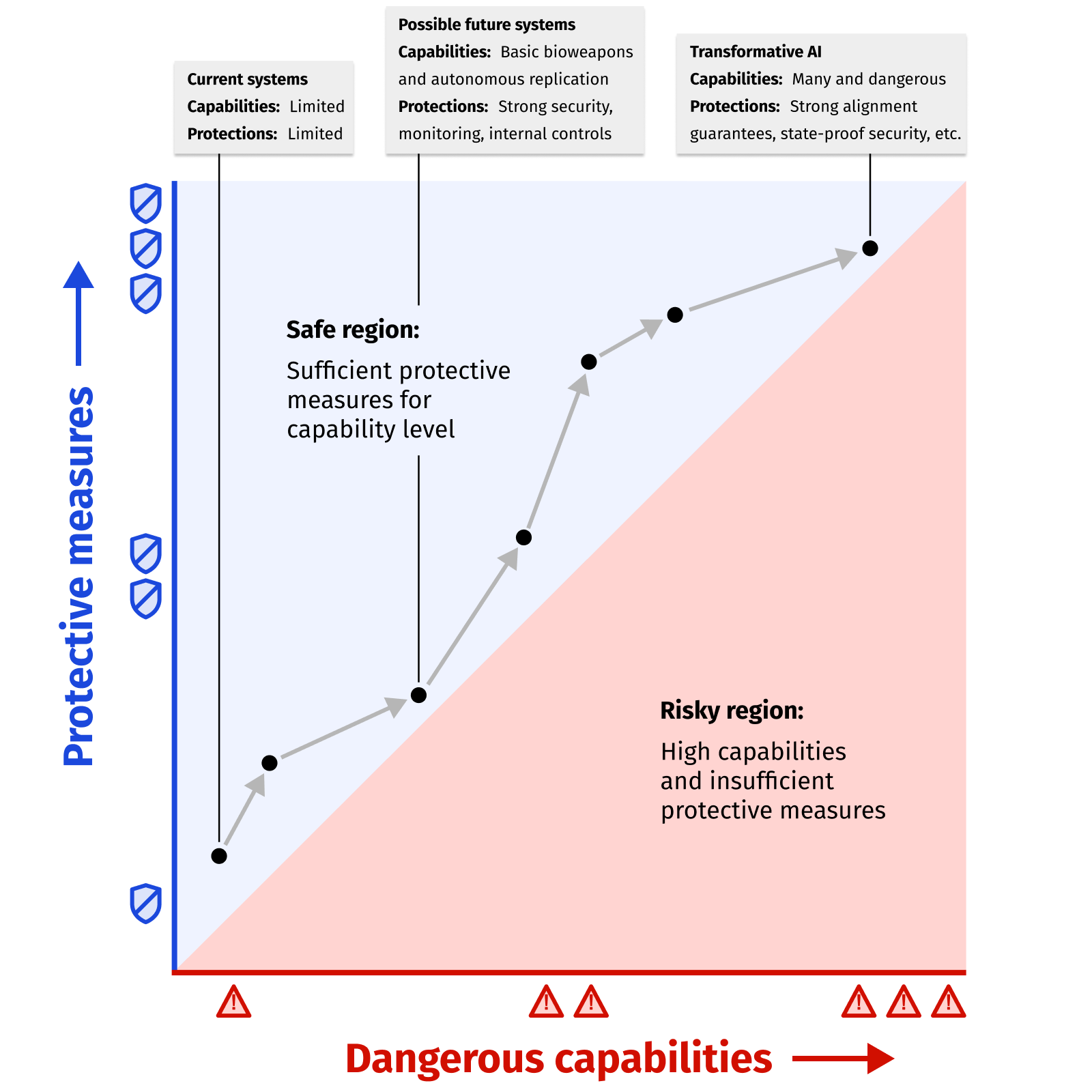
Notably, the speech in which he introduced this framing came soon after an influential blog post from AI evaluations group METR which included a similar graph with dangerous capabilities on the x axis and protective measures on the y axis, suggesting his thinking may have been influenced by METR’s work.
In the article, Zhang uses the term "intelligent robots," zhìnéng jīqìrén 智能机器人, but he is using it broadly to refer to AI systems (much as "bot" is used in English).
Zhang's statement implies that superintelligence is defined by the possession of "subjective consciousness," zhǔguān yìshí 主观意识. Here, this term is likely referring to a combination of coherent long-term goals, situational awareness, and strategic planning ability, which would render an AI system an effectively independent strategic actor, potentially a highly capable one.
Super interesting, thanks for writing!
The well of Chinese thinking here seems narrow and shallow, given that these are the senior folks you've selected for having relevant thoughts. Do you have a sense of how healthy the broader Chinese AI safety ecosystem is? (Should someone make an Alignment Forum But WeChat?)
Actually, lemme take a look myself. Looking at the CSET Map of Science, there are only 8 AI safety research clusters with >10% Chinese paper share. [https://sciencemap.eto.tech/?ai_safety_pred=30%2C64&china_affiliation_share=10%2C100&mode=list]
The relevant clusters' topics are:
* Adversarial robustness and backdoors: Clusters 60, 11944, and 33998.
* Explainability: Cluster 751.
* Safe reinforcement learning: Cluster 18683. (Fun note: this includes the classic "Concrete problems in AI safety" paper.)
An edge case is Cluster 75898, on autonomous driving, which includes a bunch of multi-agent interaction theory.
Interesting (but reasonable) that most AI safety convos happen in academia or academic adjacent labs/startups (Zhipu). Probably a good thing for public and policy awareness, given the aura surrounding academia. Hopefully one day BAAI or SHLAB will become China's real AISI.